|
I am a MS student in Seoul National University, studying deep learning and computer vision under the supervision of professor Nojun Kwak. I also had great time during my research internship at NAVER Language and Vision team. Special thanks to Donghyeon Jeon and Soonhwan Kwon. I'm currently interested in leveraging the knowledge of foundational models for diverse downstream tasks, such as generative model, and multi-modal representations. Email / CV / Google Scholar / Github |

|
I'm currently open to job opportunities. Please feel free to contact me if you have a position you think would be a good fit.
|
|
|
|
|
|
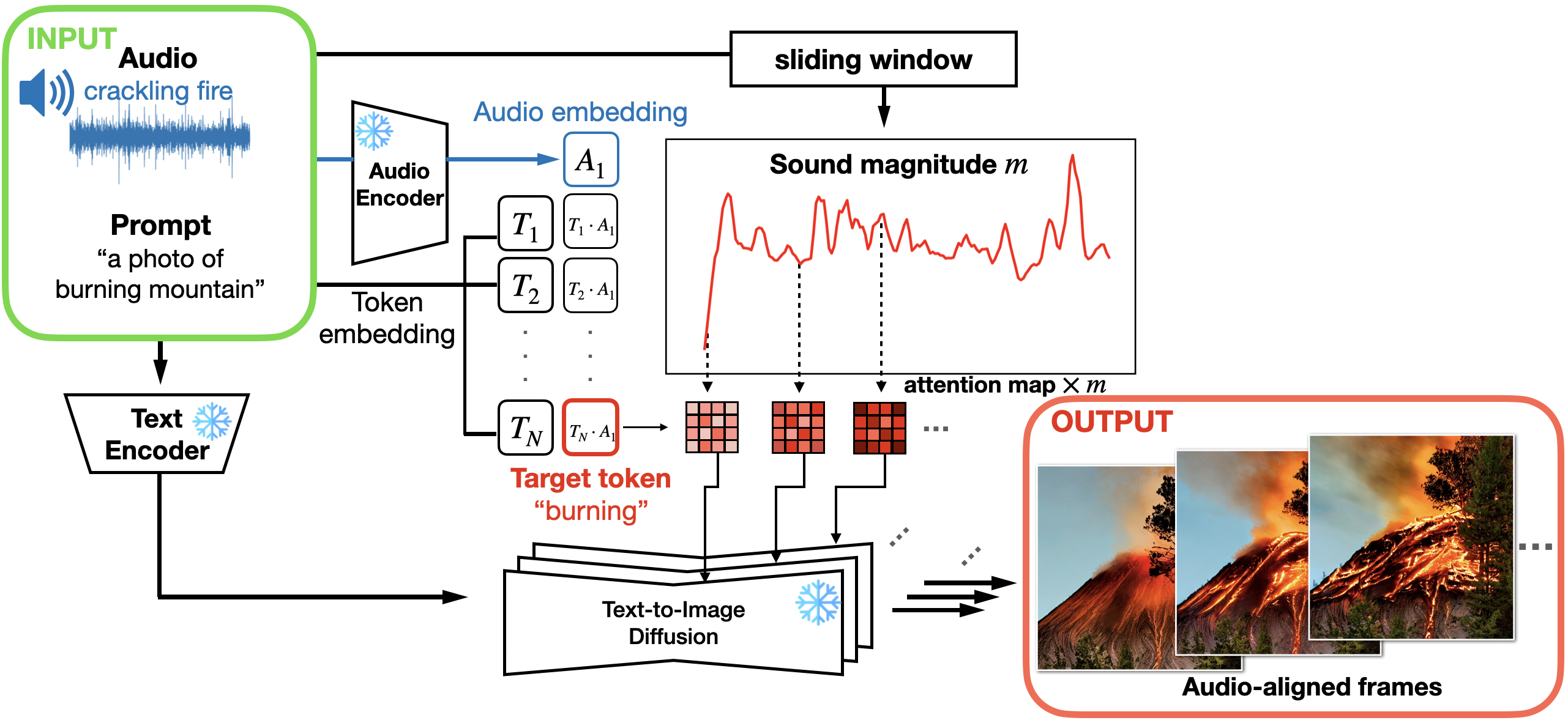
Seungwoo Lee, Chaerin Kong, Donghyeon Jeon, Nojun Kwak CVPR 2023 Workshop on AI for Content Creation arXiv We introduce a simple framework for audio-aligned text-to-video synthesis that employs an off-the-shelf text-to-image diffusion model. |
|
|
Diffusion model for anything at NAVER:
|
|
The template is from Jon Barron. Thank you for sharing! |